transfer learning (전이 학습)
= 새로운 task를 수행하는 모델을 만들 때, 기존에 학습했던 지식을 재사용하는 것

=> transfer learning 적용 시 기존 LLM보다 학습 속도가 빨라지고, 새로운 task를 더 잘 수행할 수 있음
e.g. BERT (Bidirectional Encoder Representations from Transformers) , GPT (Generative Pre-trained Transformer)
=> transfer learning 적용 이전의 기존 모델들은 task를 처음부터 학습했었다!!
task1 = upstream task (학습 데이터 말뭉치를 통해 문맥을 이해하는 task) : pretrain
= 문맥을 모델에 내재화
e.g.1 다음 단어 맞추기 : GPT
"티끌", "모아" 다음에 올 단어를 예측할 것이고, 학습 데이터 말뭉치에 "티끌 모아 태산"이라는 구 (phrase)가 많다고 할 때 모델은 이를 바탕으로 "태산"이라는 단어를 예측함
=> "태산" 이라는 단어에 해당하는확률은 높이고 나머지 단어에 대한 확률은 낮추는 방향으로 모델 업데이트
=> 모델이 대규모 말뭉치를 가지고 이런 과정을 반복 수행하게 되면, 이전 문맥을 고려했을 때 어떤 단어가 그 다음에 오는 것이 자연스러운지 알 수 있게 됨 (= 풍부한 문맥을 이해할 수 있게 됨)
=> "다음 단어 맞추기"로 upstream task를 수행한 모델 = LM (Language Model)이라고 함
e.g.2 빈칸 채우기 : BERT
"티끌", "태산" 사이에 올 단어를 예측할 것이고, 많은 말뭉치 데이터를 가지고 빈칸 채우기를 반복 학습한다면 앞뒤 문맥을 보고 빈칸에 올 단어 예측 가능
=> "모아"라는 단어에 해당하는 확률은 높이고 나머지 단어에 관계된 확률은 낮추는 방향으로 모델 업데이트
=> "빈칸 채우기"로 upstream task를 수행한 모델 = MLM (Masked Language Model)이라고 함
다음 단어 맞히기, 빈칸 채우기와 같은 upstream task들은 강력한 힘을 가짐
: 글 (= 대규모 말뭉치)만 있으면 수작업 없이도 다량의 학습 데이터를 저렴한 가격에 만들어낼 수 있음 !!
=> upstream task를 수행한 모델은 성능이 기존보다 월등히 좋음
=> 데이터 (여기서는 말뭉치 데이터) 내에서 정답을 만들고 이를 바탕으로 모델을 학습하는 방법 = 자기 지도 학습 (Self-Supervised Learning)
task2 = downstream task (자연어 처리의 구체적인 문제들)
= 우리가 풀어야 할 자연어 처리의 구체적인 과제들
=> downstream task들은 pretrain을 마친 모델을 구조 변경 없이 사용 / + task module 해서 수행
본질 = 분류 (classification) : MLM (문장 생성 제외) 사용
자연어를 입력 받아 해당 입력이 어떤 범주에 해당하는지 확률 형태로 반환
학습 방식 = 파인 튜닝 (fine tuning)
= pre train을 마친 모델을 downstream task에 맞게 업데이트하는 기법
e.g. task2 = 문서 분류라면, pre train을 마친 BERT 모델 전체를 문서 분류 데이터로 업데이트
e.g. task2 = 개체명 인식이라면, pre train을 마친 BERT 모델 전체를 개체명 인식 데이터로 업데이트
1. 문서 분류
= 자연어 (문서 / 문장) 입력 받아 해당 입력이 어떤 범주에 속하는지 그 확률값을 반환
범주에는 긍정, 부정, 중립, ..., 이 있음

=> 노란색 실선 박스 = pre train을 마친 MLM / 초록색 실선 박스 (= 작은 모듈) = 문서 전체의 분류 범주
* CLS, SEP은 문장의 시작, 끝에 붙이는 특수한 token이므로 일단 pass
2. 자연어 추론
= 문장 2개 입력받아 두 문장 사이의 관계의 범주에 대한 확률값 반환
범주에는 참 (entailment) / 거짓 (contradiction) / 중립 (neutral) / ... 등 존재

=> 노란색 실선 박스 = pre train을 마친 MLM / 초록색 실선 박스 (= 작은 모듈) = 두 문장 사이의 관계 범주
3. 개체명 인식
= 자연어 (문서 / 문장) 입력 받아 단어별로 기관명 / 인명 / 지명 등 어떤 개체명 범주에 속하는지 그 확률값 반환

=> 노란색 실선 박스 = pre train을 마친 MLM / 초록색 실선 박스 (= 단어별 작은 모듈) = 각각의 개체명 범주
4. 질의응답
= 자연어 (질문 + 지문) 입력 받아 각 단어가 정답의 시작일 확률값과 끝일 확률값을 반환
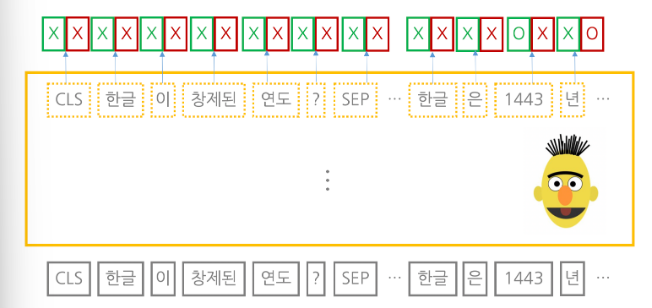
=> 노란색 실선 박스 = pre train을 마친 MLM /
초록색 실선 박스 (= 단어별 시작 작은 모듈) , 빨간색 실선 박스 (= 단어별 끝 작은 모듈)
5. 문장 생성 : GPT (LM)
= 자연어 (문장) 입력 받아 어휘 전체에 대한 확률값을 반환
*확률값 = 입력된 자연어 (문장) 다음에 올 단어로 얼마나 적절한지를 나타내는 점수

=> pre train을 마친 언어 모델을 구조 변경 없이 그대로 사용!!!
문맥에 이어지는 적절한 다음 단어를 분류
downstream은 모두 fine tuning으로 학습하지만, 사실 downstream task 학습 방법은 크게 세 가지임
=>
1. fine-tuning : downstream task 데이터 전체를 사용 -> 모델 전체를 업데이트
2. prompt tuning : downstream task 데이터 전체를 사용 -> task에 맞게 모델 일부만 업데이트
3. in-context tuning : downstream task 데이터 일부만 사용 -> 모델 업데이트 안 함!!!
3-1. zero-shot learning : downstream task 데이터 전혀 사용 x -> 모델이 바로 downstream task 수행
3-2. one-shot learning : downstream task 데이터 1건만 사용 -> 모델은 해당 건수가 어떻게 수행되었는지만 참고하고 downstream task 수행
3-3. few-shot learning : downstream task 데이터 몇 건만 사용 -> 모델은 해당 건들이 어떻게 수행되었는지 참고해 바로 downstream task 수행
=> 사실 언어 모델이 기하급수적으로 커지고 있음 : GPT-3의 parameter는 무려 175B 개!!
따라서
- fine-tuning으로 모델 전체를 업데이트하려면 비용이 만만치 않음
- prompt-tuning, in-context tuning 도 성능이 fine-tuning과 비슷할 때가 많음
=> in-context tuning처럼 모델을 업데이트하지 않고도 downstream task를 수행할 수 있다는 건 매우 매력적이다~~
'étude > AI' 카테고리의 다른 글
| 23'f Transformer NLP (2) | 2024.01.31 |
|---|---|
| Model Explanation : SHAP values (2) | 2023.11.22 |
| Unsupervised Learning : k-means Clustering, DBSCAN (1) | 2023.11.22 |
| Model Evaluation and Improvement : Cross - Validation (0) | 2023.11.19 |
| Ensembles of Decision Tree : RandomForest, Gradient Boosting (0) | 2023.11.18 |



