Clustering (이론)
= cluster (그룹)으로 나누는 거
비슷한 부분을 가진 포인트로 나누는 것!!

같은 색을 가진 애들끼리는 비슷하다~
= 같은 cluster에 속한다!
근데 색이 다르면 다름
저 위에서 x축을 feature A, y축을 feature B 라고 하고
A, B의 열을 가진 데이터프레임을 만들면 이때 output은 each data point에 대한 output num이 된다
(output은 target data 말하는 것이다!)
k-Means Clustering
가장 단순하고 가장 흔하게 이용되는 clustering 알고리즘
1. 특정 cluster의 cluster center를 정한다.
2. cluster center를 정하고

모든 data point에 대해서 모든 data를 돌아다니며 거리를 계산한다
3. 모든 data와 특정 data center와의 거리를 모두 계산해서 가장 가까운 data center로 classify한다.

=> 그러면 이렇게 됨!
4. each cluster에서 data point의 평균을 계산할거임
=> 초록이들끼리 평균 계산, 빨강이들끼리의 평균 계산, 파랑이들끼리의 평균 계산
=> 그렇게 해서 새로운 cluster center를 정한다

=> 그러면 이렇게 됨!
5. 이제 모든 data point들과 각 cluster center와의 거리를 계산해서
거리가 가까운 애들을 new cluster center로 정한다

=> 이케 되지
6. 그러면 또 각 cluster의 평균을 계산해서 그 위치를 cluster center로 정한다

이 과정을 cluster center가 바뀌지 않을 때까지 반복하는 것이 k - Means Clustering이다
: 평균 계산해서 새로 center 정하고 -> 각 center와의 거리 재서 cluster 새로 정하고 -> 각 cluster의 평균 계산해서 새로 center 정하고 -> ...
k - Means Clustering failed??
1.

여기서 cluster와 좀 떨어져 있는 애들의 경우 걔들끼리는 같은 cluster여야 하는데
k - Means Clustering에서는 그냥 거리만 계산하는 거다 보니 그게 안 됨
2.

3.
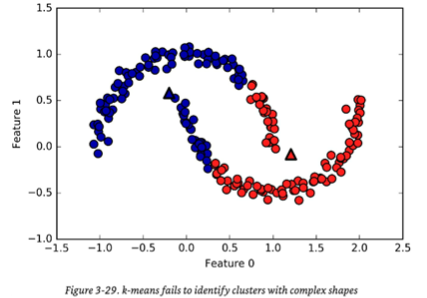
2번과 3번도 마찬가지
=> DBSCAN을 통해 이 문제점을 해결할 수 있다!
DBSCAN?
: Density based Spatial Clustering of Applications with Noise
밀집도를 보고 Clustering을 수행한다
mechanism
= 밀도 (Density)를 기반으로 data들을 나눈다
- eps = 지역 사이즈
- min_sample = 같은 cluster가 되기 위해 eps 안에 들어와야 하는 최소한의 data 수
- core sample : 특정 cluster의 core가 되는 sample
- boundary sample : 특정 cluster의 경계가 되는 sample
1. 특정 data (A)를 중심으로 eps안에 있는 모든 data 개수 탐색
2. eps 안에 해당하는 data가 min_sample 이상이면, A를 중심으로 하는 cluster 생성
3. 만약 특정 data B를 중심으로 생성된 cluster와 A를 중심으로 하는 cluster가 만난다면
두 cluster는 하나의 cluster로 간주한다.
4. 1 ~ 3의 과정을 반복
experiment

1. min_sample = 2일 때 eps를 늘려보자

2. min_sample = 3일 때 eps를 늘려보자

3. min_sample = 5일 때 eps를 늘려보자

min_sample, eps가 작으면 data 수가 적어도 cluster생성이 가능하다
Code : noise 예시
dbscan = DBSCAN(eps=0.01, min_samples=2)
clusters = dbscan.fit_predict(X_scaled)
LABEL_COLOR_MAP = {-1: 'k',
0 : 'r',
1 : 'b',
2 : 'g',
3 : 'c',
4 : 'y',
5 : 'pink',
6 : 'k'}
label_color = [LABEL_COLOR_MAP[l] for l in clusters]
# plot the cluster assignments
plt.scatter(X_scaled[:, 0], X_scaled[:, 1], c=label_color, cmap=mglearn.cm2, s=60)
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
결과 :

eps를 너무 작게 줘서 나머지 검은색들이 모두 noise로 분류됨
빨강이 cluster와 파랑이 cluster 속 data들이 같은 cluster로 분류된 것
'étude > AI' 카테고리의 다른 글
| 23'f Transformer NLP (2) | 2024.01.31 |
|---|---|
| Model Explanation : SHAP values (2) | 2023.11.22 |
| Model Evaluation and Improvement : Cross - Validation (0) | 2023.11.19 |
| Ensembles of Decision Tree : RandomForest, Gradient Boosting (0) | 2023.11.18 |
| transfer learning (upstream, downstream) (0) | 2023.11.15 |


