머신언러닝 Machine Unlearning은 삭제 요청된 데이터를 모델에서 효과적으로 삭제하면서도 나머지 데이터, 즉 보존해야 할 데이터에 대한 성능은 보존하는 것을 목표로 한다.
삭제 요청된 데이터를 아예 포함하지 않고 나머지 데이터로만 모델을 학습시킨 상태인 Retrain이 이상적인 상태이다.
이 논문에서 Retrain과 머신언러닝된 모델의 유사도를 측정하는 평가 지표는 RA, FA, TA이다.
=> 각각 Retain Accuracy, Forget Accuracy, Test Accuracy로 보존해야 할 데이터에 대한 분류 정확도, 삭제 요청 데이터에 대한 분류 정확도, 그리고 일반화를 위해 테스트 데이터셋에 대한 분류 정확도이다.
기존 baseline도 간단히 설명하면,
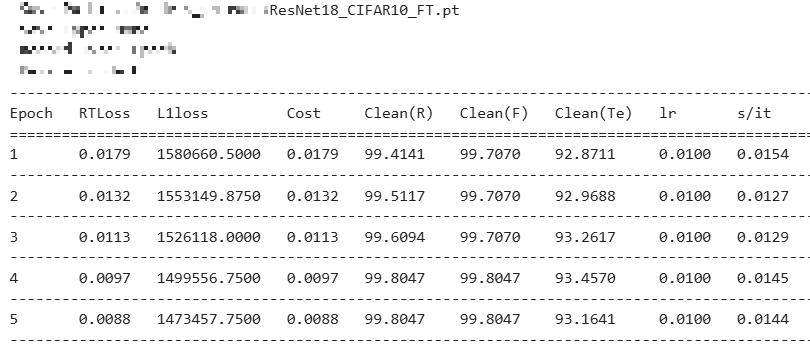
FineTune은 보존해야 할 데이터로만 다시 학습하는 방법,
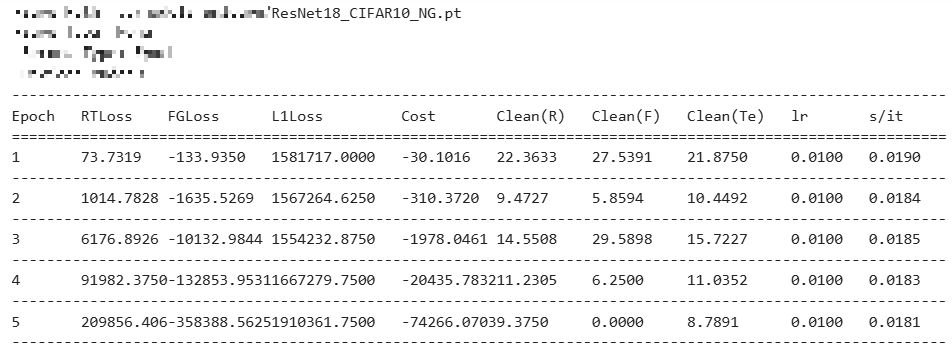
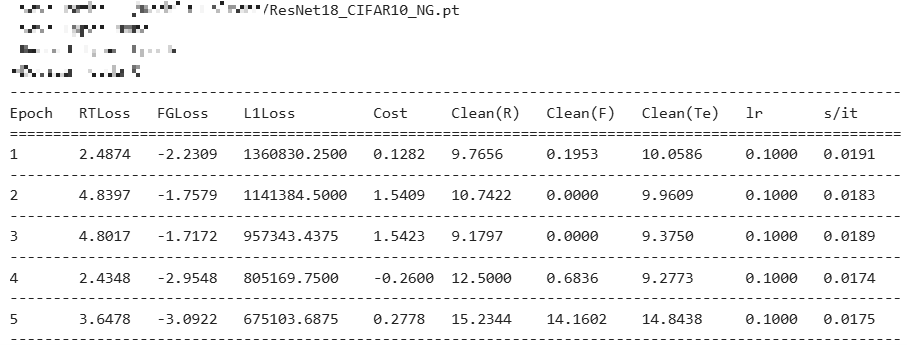
NegGrad는 삭제 요청된 데이터의 Loss를 최대화하는 방법,
RandomLabel은 삭제 요청된 데이터의 logit에 답이 아닌 다른 라벨을 랜덤으로 배정해서 다시 학습시키는 방법,
FisherForget은 삭제 요청된 데이터에 민감하게 반응하는 파라미터만을 조정하는 방법,
InfluenceUnlearning은 삭제 요청된 데이터 각각이 만든 파라미터 변화량을 계산해서 그대로 역으로 제거하는 방법이다.
각 방법의 원리는 또 논문 리뷰하면서 쓰겠지만, 여기서는 딱히 자세히 몰라도 된다.
https://openreview.net/forum?id=kAuckbcMvi
Unlearning-Aware Minimization
Machine unlearning aims to remove the influence of specific training samples (i.e., forget data) from a trained model while preserving its performance on the remaining samples (i.e., retain data)....
openreview.net
ResNet18 모델로 CIFAR10 데이터셋을 pretrain한 후,
random forgetting으로 언러닝한 모델의 RA, FA, TA 를 구했다.
여기서 random forgetting은 pretrain에서 학습한 데이터셋의 일정 비율만큼을 랜덤으로 잊는 언러닝 방법이다.
github 의 파라미터를 참고해서 실험했으며, 전체 데이터의 10%를 랜덤으로 잊도록 설정했다.
| Accuracy[%] | RA | FA | TA |
| Retrain | 99.30% | 91.78% | 91.32% |
| FineTune | 99.95% | 99.78% | 92.95% |
| NegGrad | 15.11% | 14.98% | 14.96% |
| RandomLabel | 98.40% | 98.10% | 91.14% |
| FisherForget | 98.08% | 97.60% | 89.57% |
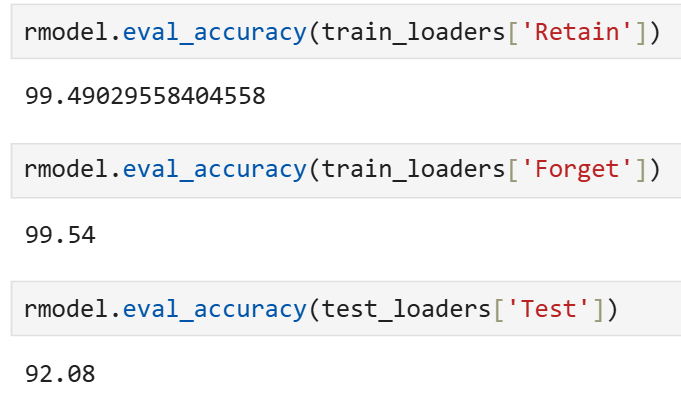
| Influence | 99.49% | 99.54% | 92.08% |
| UAM | 99.67% | 96.32% | 91.56% |
논문은 비전 모델과 언어모델을 모두 사용해서 검증했지만 나는 일단 비전 모델만 가지고 실험해봤다.
FT의 경우 forget이 충분히 되지 않고, NG의 경우 모델의 원래 성능이 급격히 붕괴하는 것을 확인할 수 있다.
UAM은 FT와 NG를 같이 다루되, 단순 가중합이 아니라 구조적으로 분리해야 하는 방법을 제시하고
이를 기존의 벤치마크와 코사인 유사도를 이용한 모델의 구조에서 증명한다.
UAM : Unlearning-Aware Minimization 기본 원리
I. 기본 아이디어
삭제 요청된 데이터셋을 Df, 보존해야 할 데이터셋을 Dr, 손실함수를 L이라고 했을 때,
UAM은 한 번의 학습 시 아래의 두 단계가 일어난다 :
1. forget loss를 최대화하는 maximization

2. 그 상태에서 retain loss를 다시 최소화하는 minimization

즉 1번으로 forget 이 잘 일어나는 위치를 먼저 찾아놓고, 2번에서 모델의 성능을 다시 복구하는 방식이다.
논문은 각 단계의 유도 과정을 수식으로 증명해준다.
먼저 1,2번 모두 w는 현재 모델의 parameter이고, Forget loss를 최대화하는 parameter를 찾기 위해 w+ ẟ를 사용한다.
1번의 유도과정은 다음과 같다 :
Retrain의 parameter인 w*는 Df의 loss를 최대화하는 범위 안에 있을 것이다.
=> 당연하다! Df를 애초에 학습한 적이 없기 때문이다.
따라서 우리가 찾는 parameter인 ŵ 역시 Df의 loss를 최대화하는 범위 안에 있어야 한다.
이를 식으로 표현하면 다음과 같다 :

여기서 ρ는 임의로 배정한다. 논문 Ablation C1에 따르면 ρ = 2.0에서 언러닝 성능이 가장 좋았다고 한다.
이렇게 해서 나온 식이 아래와 같다 :

II. 증명
위의 UAM 식을 1차 Taylor Expansion 등으로 잘 정리하면 다음과 같은 식을 유도할 수 있다 :

여기서 γ는 유도 후 Hessian을 표현하기 위해 나온 상수이다. Hessian의 computational burden을 줄이기 위해서다.
이 Hessian을 빼는 게 제일 좋겠지만, Hessian을 포함하는 게 unlearning 성능에 중요하다고 한다.

확실히 Hessian을 포함해야 더 적은 epoch로 이상적인 성능에 다다를 수 있음을 알 수 있다.
참고로 γ=1.7에서 언러닝 성능이 가장 좋았다고 한다.
III. Geometric interpretation
논문은 수학적 증명에서 그치지 않고 Df와 Dr가 구조적으로 다르다는 것을 증명한다.
UAM이 Df와 Dr의 loss 사이의 내적값을 최소화하는 것에서 알 수 있는데, 이 내적값은 코사인 유사도값으로 계산한다.
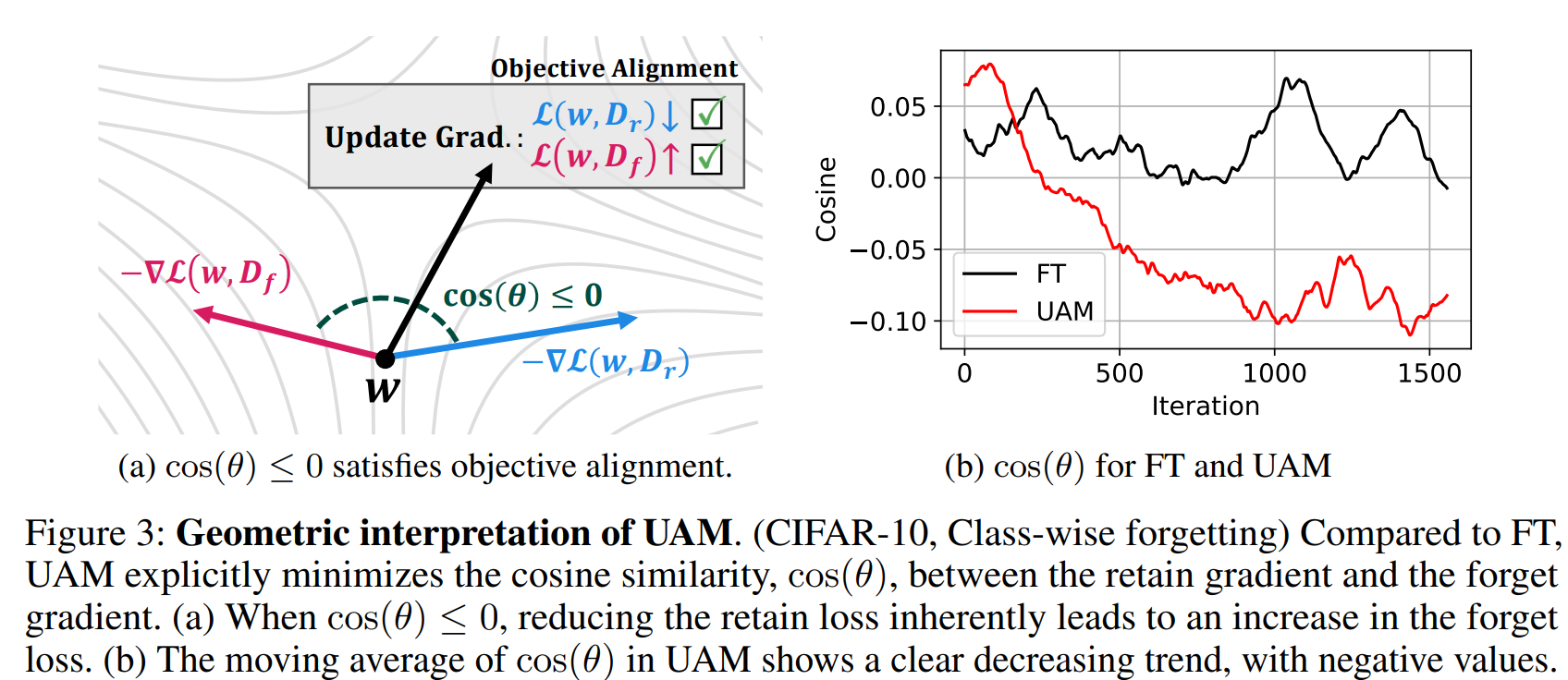
Fig.3b를 보자. θ는 Dr와 Df gradient 사이의 각도이고, iteration이 늘어날수록 UAM에서는 이 값이 계속해서 작아진다.
cosπ/2 = 0니까, 두 gradient가 구조적으로 계속해서 멀어지고 있음을 알 수 있다.
Dr로 다시 학습해서 언러닝하는 FT와 비교해봐도 UAM이 Dr와 Df 사이의 차이를 더 효과적으로 벌린다는 것을 확인할 수 있다.
기존 baseline 실험 결과 첨부 :
Retrain

FineTune

NegGrad
RandomLabel

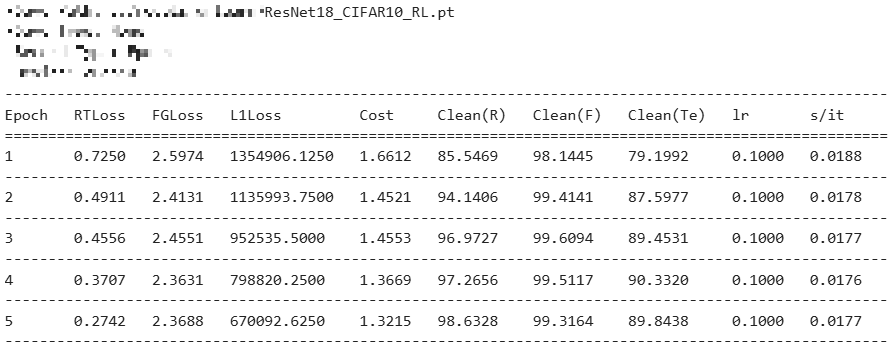
FisherForget

Influence
저자의 홈페이지는 아래와 같다.
https://trustworthyai.co.kr/article/2025/uam/
혼자 논문 분석해보고 싶어서 아직 안 읽어봤다.
'étude > 논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] Amnesiac Unlearning (0) | 2025.02.07 |
|---|---|
| [논문 리뷰] Evaluating Machine Unlearning via Epistemic Uncertainty (2) | 2025.01.20 |
| [논문 리뷰] Remember What You Want to Forget: Algorithms for Machine Unlearning (1) | 2025.01.16 |
| [논문 리뷰] CLEAR : Character Unlearning in Textual and Visual Modalities (4) | 2024.12.30 |
| [논문 리뷰] Designing a Dashboard for Transparency and Control of Conversational AI (3) | 2024.12.09 |



